
其实我早上已经看到了学长的消息,本来是打算整理一下最近的实验进展再仔细回复的,结果下午跑实验跑忘了(改了一个很小的环节居然超了SOTA又多了一些,无心插柳的哭笑不得)。如我所料,实验没能赶上ICCV,目前还在代码调试阶段,遇到了一些瓶颈问题,想借此机会向学长简单请教一下。
之前我们提到过利用反向投射来提升3D proposal质量的环节,motivation是认为SAM的边界更准确、语义性更强。至于具体实现细节(比如是单纯补充缺失的点,还是删除未覆盖的点),需要根据实验情况进一步验证。但是各种实验结果都不是很理想,思路变化如下:
思路一:
通过SAM的2D mask反向投射回3D point cloud层面,结合深度图像中保存的深度信息,锁定SAM 2D mask认为构成proposal的点。
初步结果:
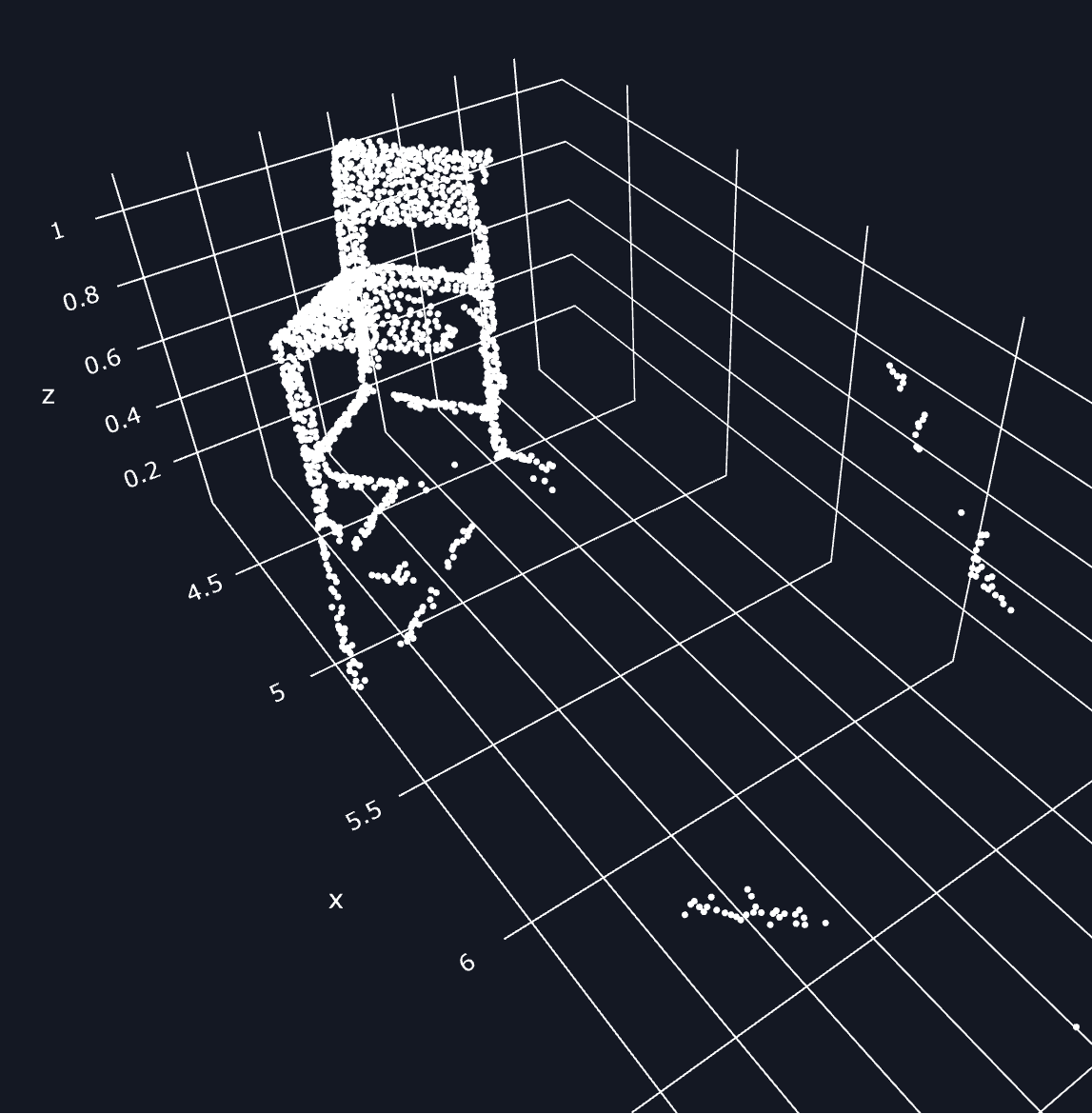
- 每个投射回去组成的噪声点非常多。SAM 2D mask边缘像素投射回去后,既有贴近目标的点,也有离散的噪声点,难以通过DBSCAN简单去除。
- 如果对场景中的每个3D point cloud单点进行迭代循环,计算速度太慢。因此,我引入了superpoint簇类来加速处理,但这种表征形式并未解决噪声问题,且superpoint簇类的尺度大小还会影响不同尺度3D proposal的质量。
- 同时还需要考虑一个多角度问题,如果只选择单一角度或者角度变化不大的2D mask那么组成的反投射点群也是片面不充分的,这里还重新设计了多角度选取mask的环节(某种程度上加强了综合理解hh)。
噪声点:
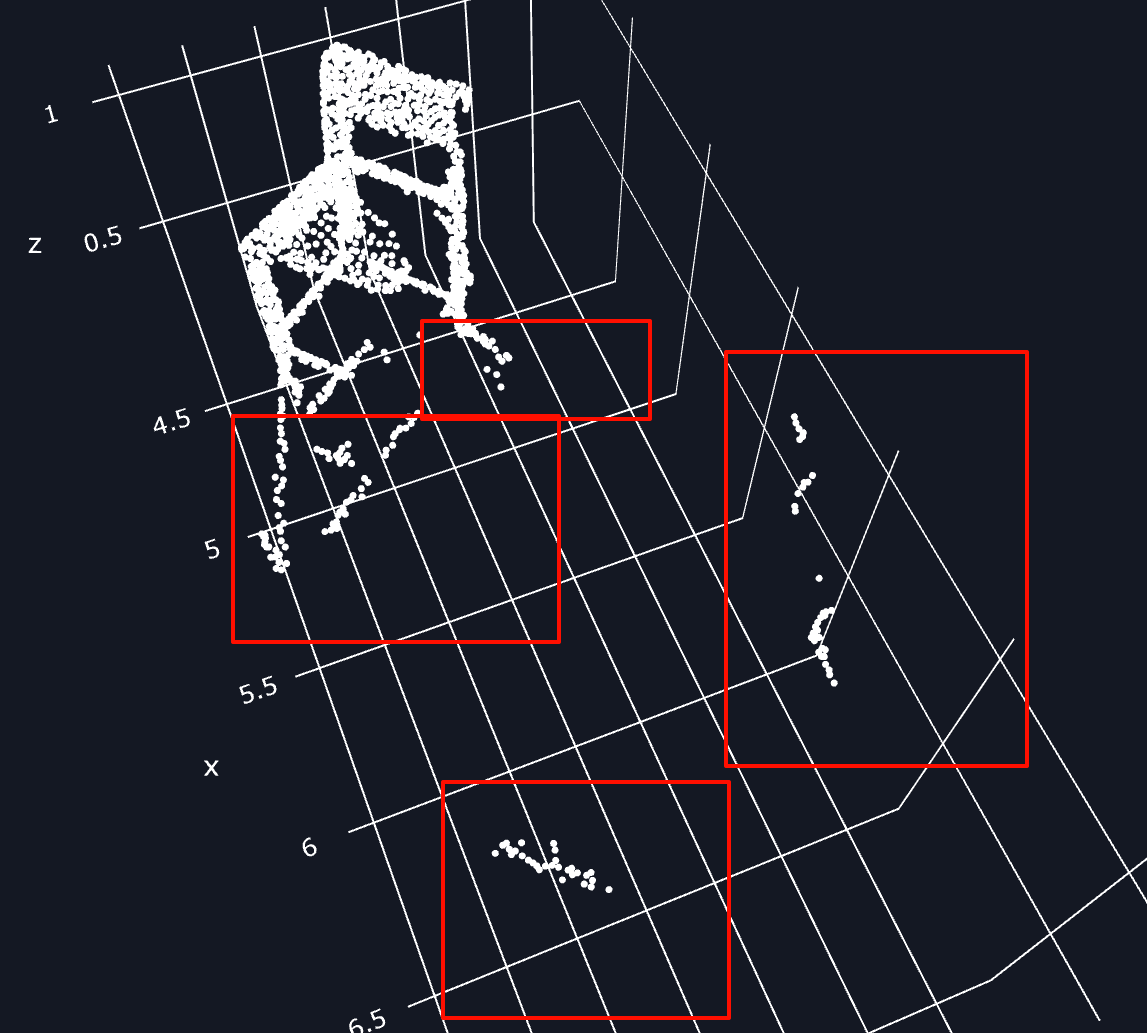


superpoint尺度大小:



思路二:
考虑将所有场景的3D点通过深度图像关系投射到2D图像中,找到对应的像素,直接利用SAM 2D mask的输出在像素层面进行覆盖与否的判断,从而优化3D mask proposal的质量。
初步结果:
- 本质上,这种方法与思路一类似,只是方向不同(2D to 3D vs. 3D to 2D),噪声问题依然存在。
- 3D point cloud直接投影到2D照片锁定像素的精度比思路一更低,导致结果不够理想。
- 同样是需要一个很大数据容器去储存每一个场景的所有单点的匹配信息运行起来计算时长不容小觑…
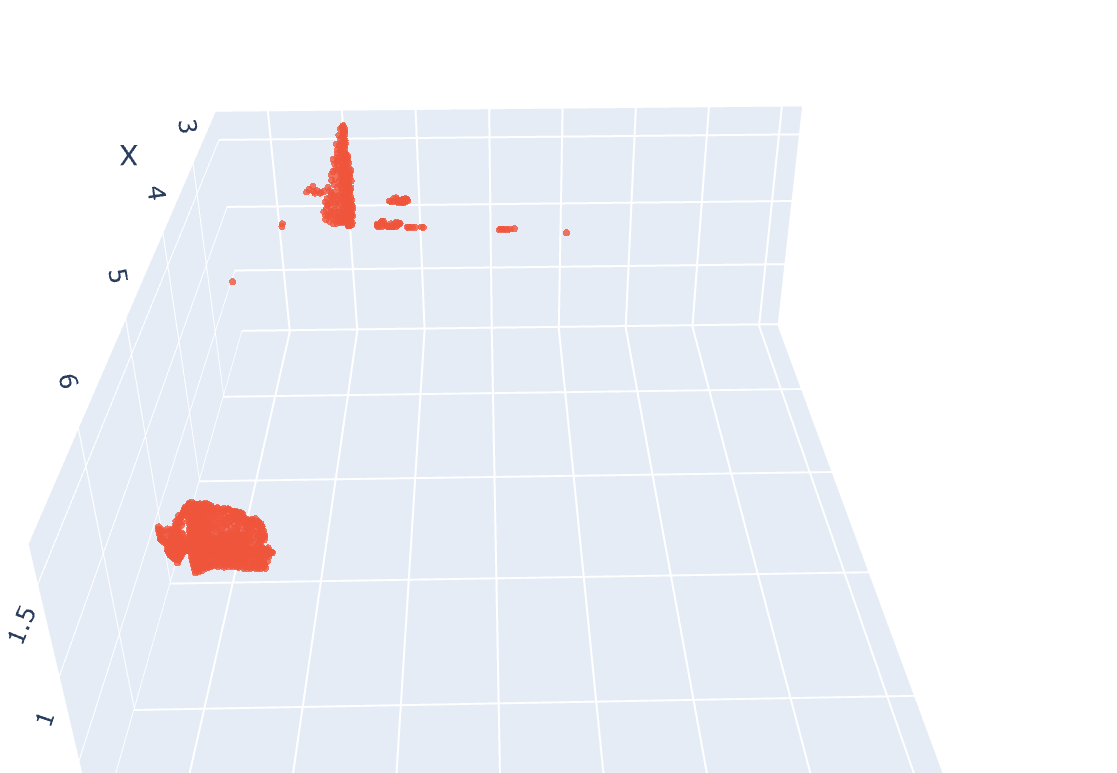
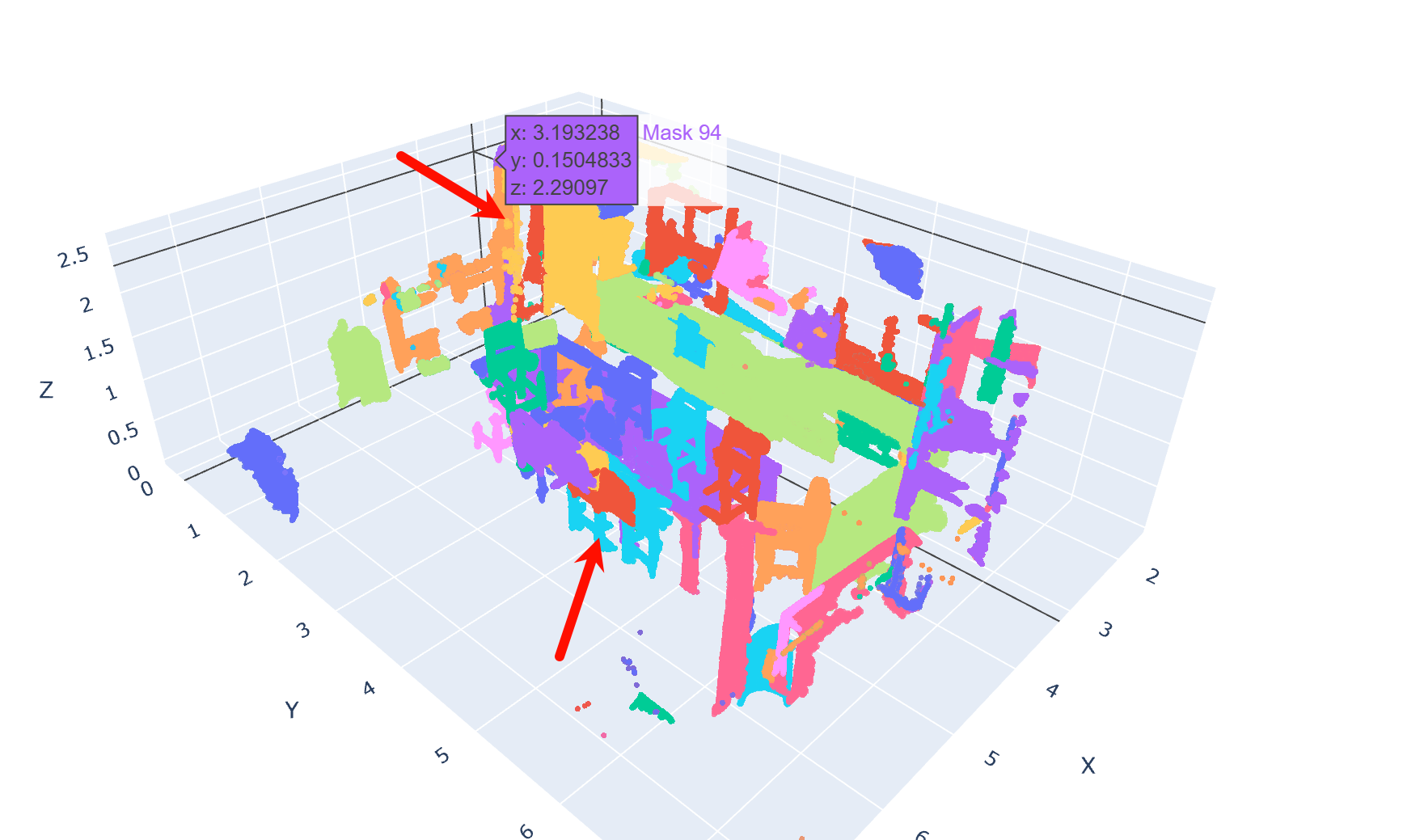
思路三:
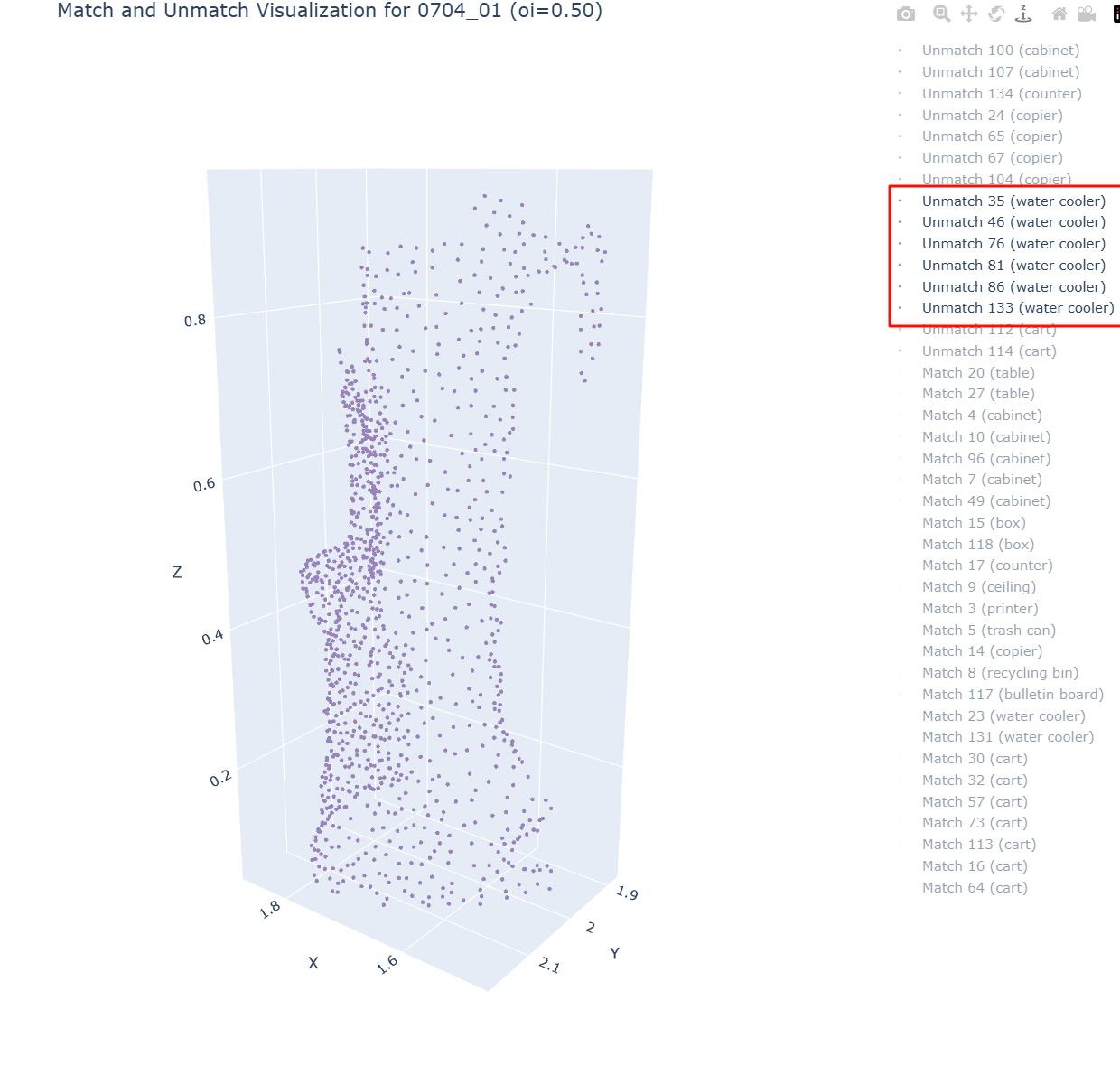
我今日很想知道这个环节的提升上限会是多少?还到底有没有提升的优先必要性呢??于是通过与ground truth (GT)直接比较,统计质量低的具体原因,发现主要问题可以归为三类:
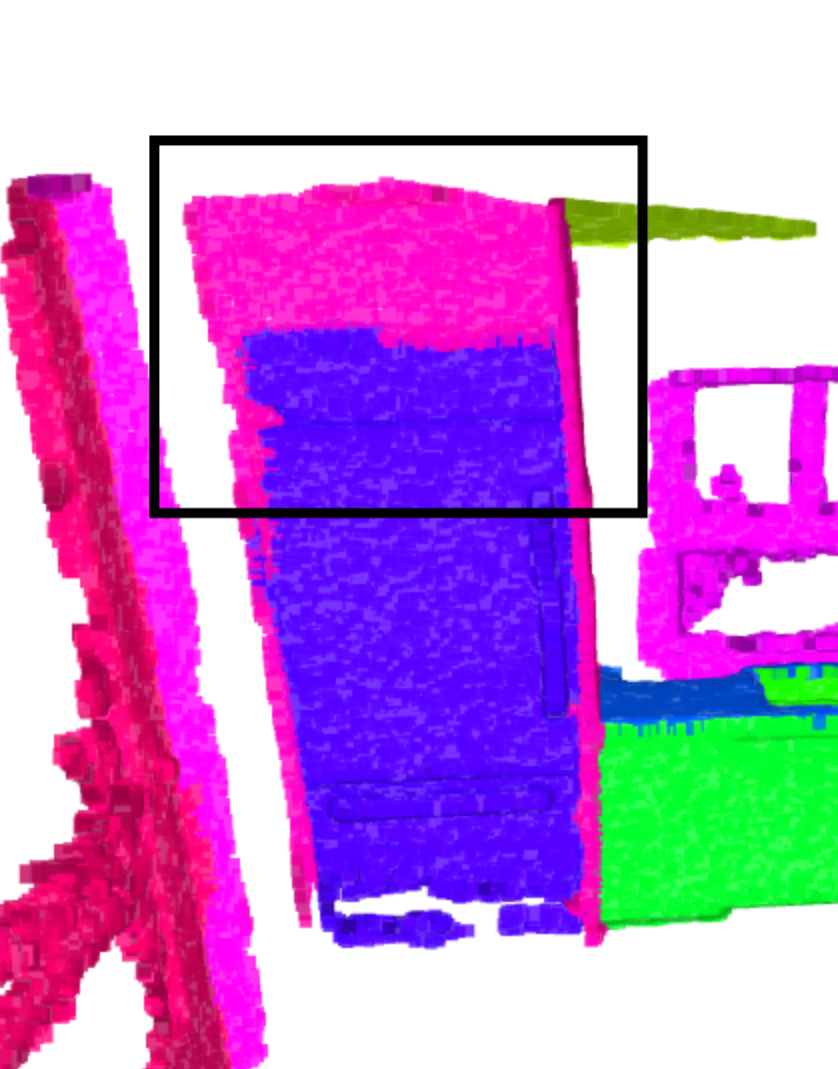
- Missing points:和gt相比漏掉了一些点 蓝色。
- Wrong points:错误加入了一些多余点 红色。
- Merge issues:尺寸需要合并的情况 大片蓝色点群。例如,一扇门被错误分割成上下两半,一个连续的折角柜子被切分成多段,导致在evaluation时,尽管分裂出的3D proposal语义label一致,但重合度不达标被筛出去了。
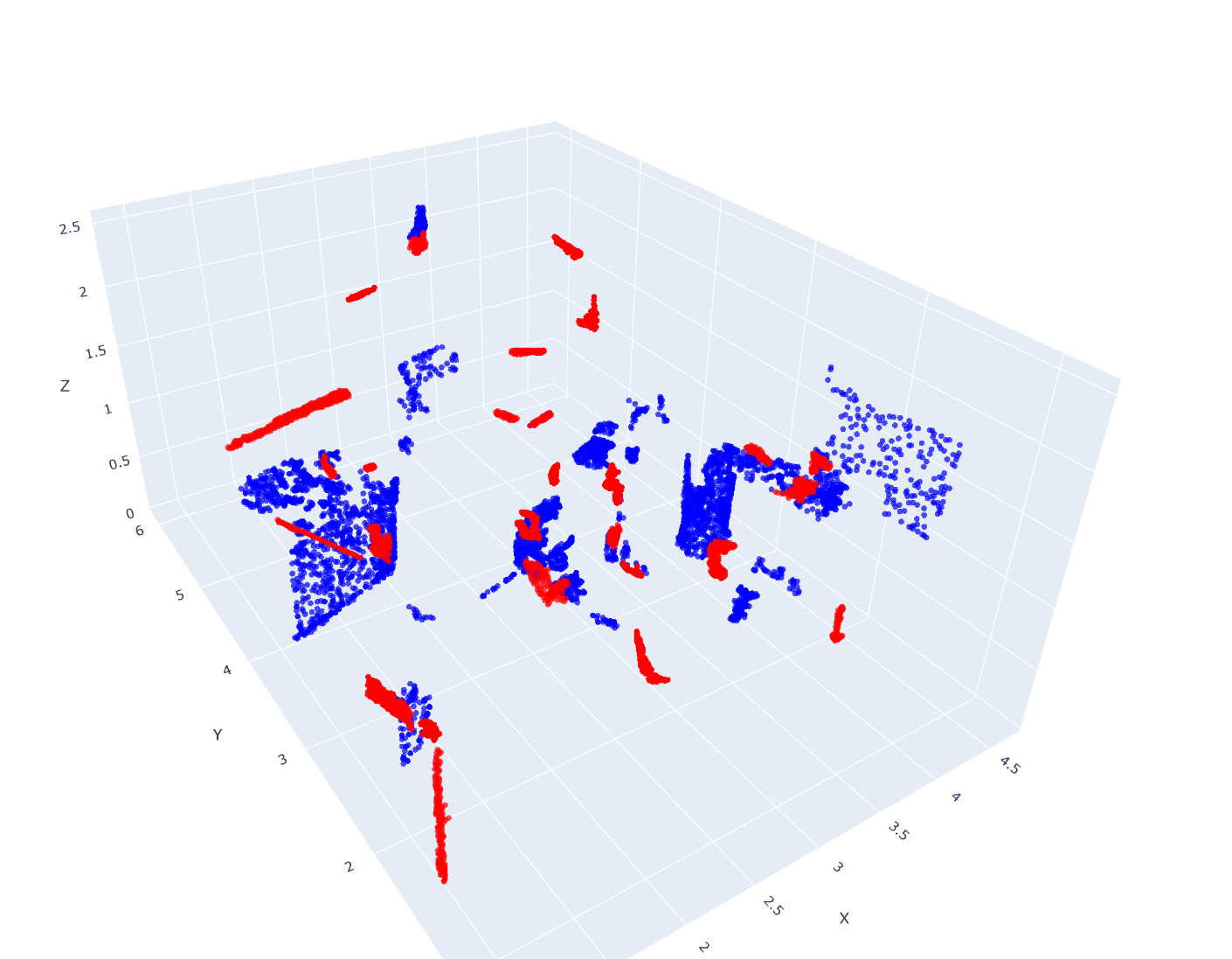
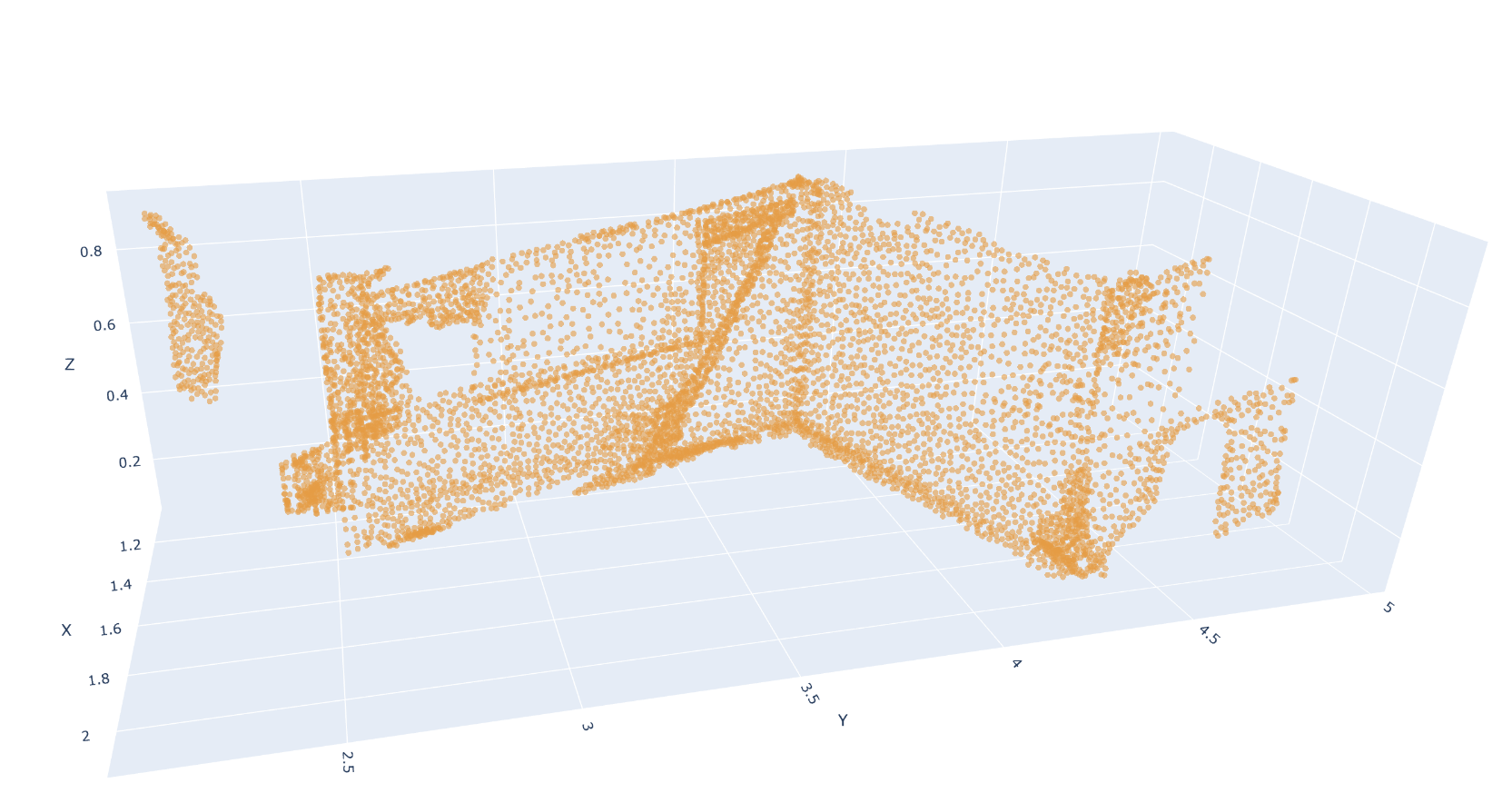
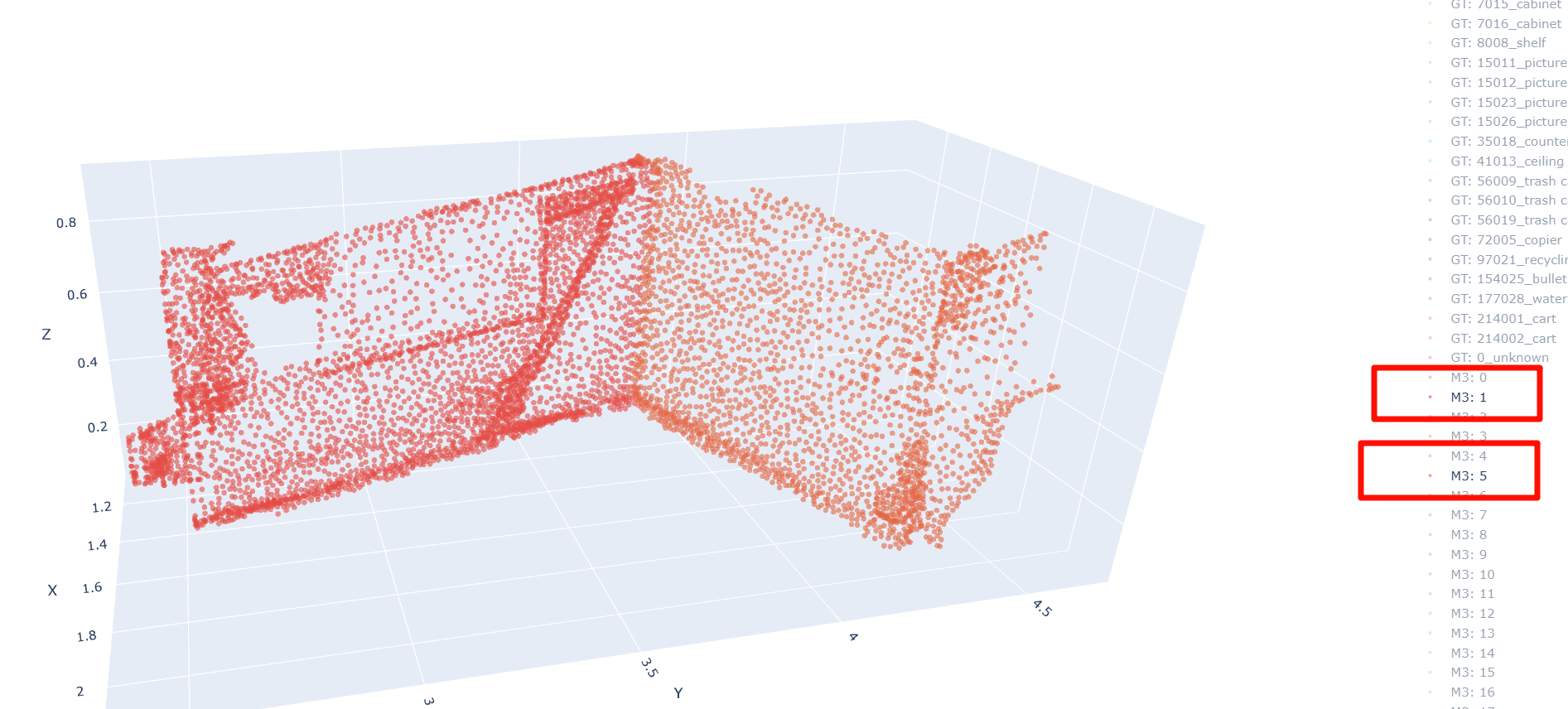
目前统计下来,第三类“merge issue”是三种问题中最常见的。因此,我的最新思路是:
在通过MaskClip为每个proposal生成初步语义label后,针对每个场景中具有相同label的mask proposals,检查它们的距离是否满足合并条件。这次我们专注于解决合并问题,暂时搁置其他点的“小修小补”(至少优先级较低哈哈)。
难点一:如何判断两个3D proposal的距离是否足够“近”?
单纯依赖空间距离可能会有问题。例如,对于并排摆放的椅子,如果一味关注距离,可能会错误地将两把独立的椅子合并成一个整体。
难点二:需要合并的proposal尺寸差异较大。
有些proposal尺寸相差悬殊,有些则相对均匀。判断相同label的3D mask proposal是否适合合并仍需实践验证。目前我主要考虑以下因素:
- 重合点数:两个proposal之间的共享点数量。
- 空间距离:两者的几何中心或边缘间距离。
- 距离最近边缘的几何特征一致性:如边缘形状或方向是否相似。
附加优化:
在观察相同label的3D mask proposals时,我发现存在大量重复度很高的情况。为此,我计划对重复度超过一定阈值的proposal,仅保留包含点数最多的那一个,以轻量化后续推理环节。
以上是目前的进展和想法,想请教学长:对于合并条件的设定或重复proposal的处理,您有没有什么建议或经验可以分享?非常期待您的看法!